tensorflow-十八弹
条评论又来到了快乐的机器学习时光,在上一讲中我们提到了如何将自定义数据转换成tensorflow输入的格式,这真是一个好消息,这样我们就可以愉快的训练我们自己的数据了,不过……(我就知道事情不会这么简单)不过自己的数据集还没有训练好,而且数据集太大了,八十几个G害怕自己的电脑受不了,不想在笔记本上跑,所以暂且没有使用自定义的数据,不过还是想看看处理效果,好奇害死猫呀,这不就开始倒腾已有的数据,在这里我训练的是pascal的数据,数据包含二十种第五n多图像,具体多少张我也不知道.我们同样是采用下面的步骤进行处理:
- 获取训练样本,样本为XML格式
- 将训练样本转换为tensorflow所需要的输入格式
- 选择模型配置文件
- 对模型进行训练,然后就是漫长的等待过程
昨晚训练了一晚上的模型,不过似乎并没有使得模型收敛,不过幸好每次都会输出checkpoint,所以也不至于前工尽弃,不过还是说明训练其实是一个很费时的过程,当然咯也跟数据量有直接关系,也跟电脑配置有关系,由于我都是采用CPU进行训练,且只是双核的CPU所以效率比较低,废话不多说,看看目前的训练效果: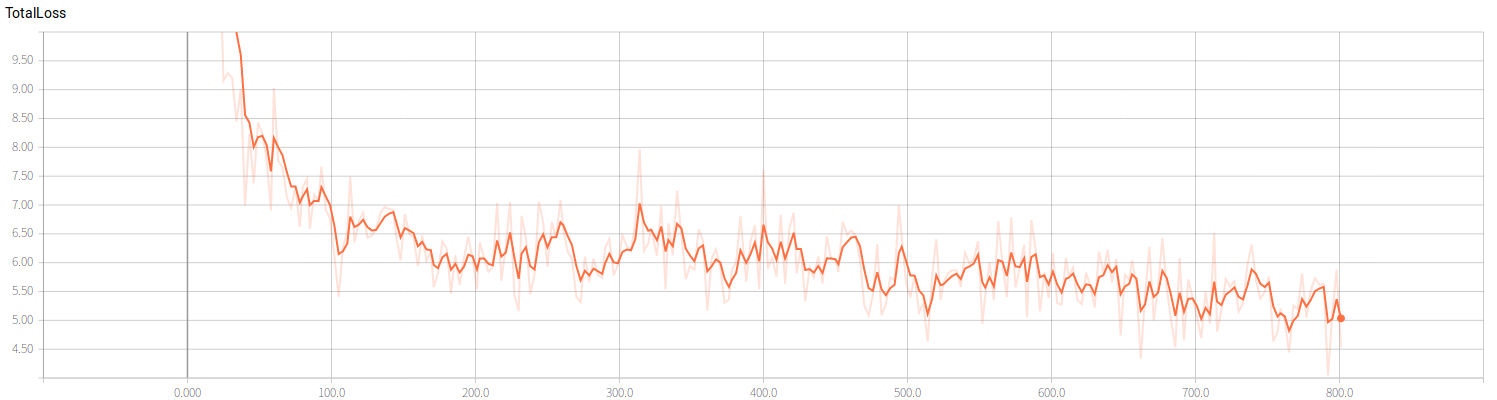
上图为全局误差的变化图,从图中我们可以看到随着训练次数的增加,误差是在下降的,但是当训练次数超过两百次之后误差下降的速度就开始变缓,同时出现震荡的现象,不过整体误差还是呈现出下降的趋势.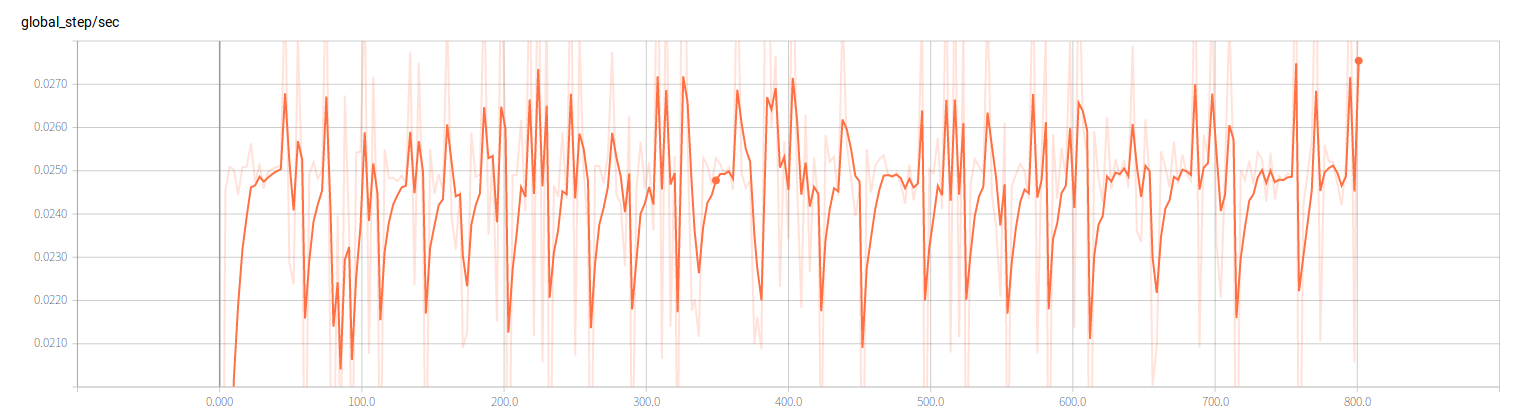
当然,我们还可以看看步长的整体变化趋势,这些信息都会在tensorboard中输出,只需要调用tensorboard查看就好了,还是很方便的,当然,最重要的是可以查看模型的 Graph,实际上由于深度学习模型比较复杂,模型图难以整体呈现,在这里就不贴模型图了,由于昨晚并没有完成训练,今天只能接着昨天的训练,不过在选择模型参数过程中直接套用的模型参数其实没有理解Fast-RCNN模型每个参数的含义,所以也不知道怎么调,下一讲会详细介绍Fast-RCNN的过程,以便于理解模型参数配置的含义.