tensorflow-第二十九弹
条评论 很久没有更新这个系列了,不知不觉tensorflow也更新到了2.x版,新版得tenforflow相比于1.x的版本,有着更快的训练速度,同时内部集成了keras使得网络的构建和训练变成了一件及其简单的事情,因此在构建网络上并没有什么可以细说的,剩下的工作我们会把代码的编写放在后一步,着重的说明各种网络的构建模式以及机器学习中的一些细节问题,以及导致这些问题的原因,由此更深入的了解如何通过机器学习对网络进行调优。
我打算花一下午的时间总结一下主要包括几个部分的问题:
- 第一个就是激活函数的问题:激活函数的类型,为什么需要激活函数,以及如何判断激活函数的好坏;
- 第二个是keras的问题,这个工具以前没有用过,所以打算用一下,顺便介绍一下其特点;
- 第三个是关于GAN的问题,在GAN中有一个重要的问题是生成器与识别器如何联合调优的问题,这个需要仔细分析;
首先我们来谈一下什么是激活函数:在神经元中,输入的 inputs 通过加权,求和后,还被作用了一个函数,这个函数就是激活函数。引入激活函数是为了增加神经网络模型的非线性。没有激活函数的每层都相当于矩阵相乘。就算你叠加了若干层之后,无非还是个矩阵相乘罢了。以上这句话引用自百度百科,实际上意思就是说对于神经网络来说,一个神经元的输入实际上就是前面一层神经元值得线性组合,如果不做任何处理,则神经网络就是多个线性函数组合,也就是说就算添加了隐藏层,最后得输出也只是最原始得输入得线性组合(证明),因此中间的隐藏层存在的意义就很有有限,而引入激活函数后,通过激活函数做一个非线性映射,使得神经网络能够对任何函数进行逼近。在了解激活函数后我们需要进一步的了解梯度消失问题: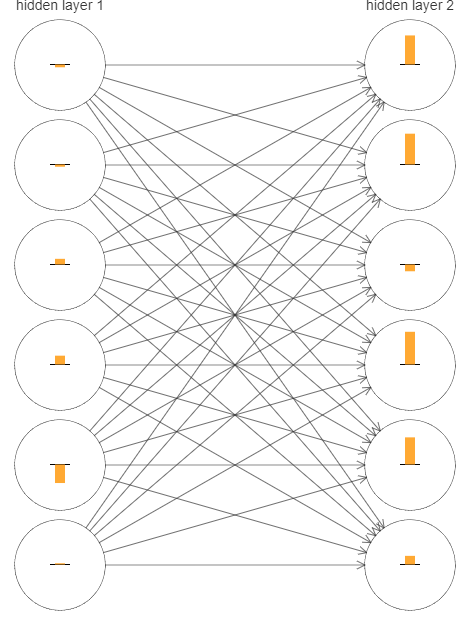
上图中的黄色矩形柱的高度代表了梯度的变化的大小,从中我们可以看到layer2中的梯度变化明显大于layer1,下面需要通过数学的方法进行证明:
假设$\delta^l_j= \partial C /\partial b^l_j$表示第l层第j个神经元的梯度,假设$\delta^1$为第一层的梯度向量,$\delta^2$为第二层的梯度向量,通过向量长度能够近似的表示某一层的学习速率,则不同层的学习速率曲线如下图: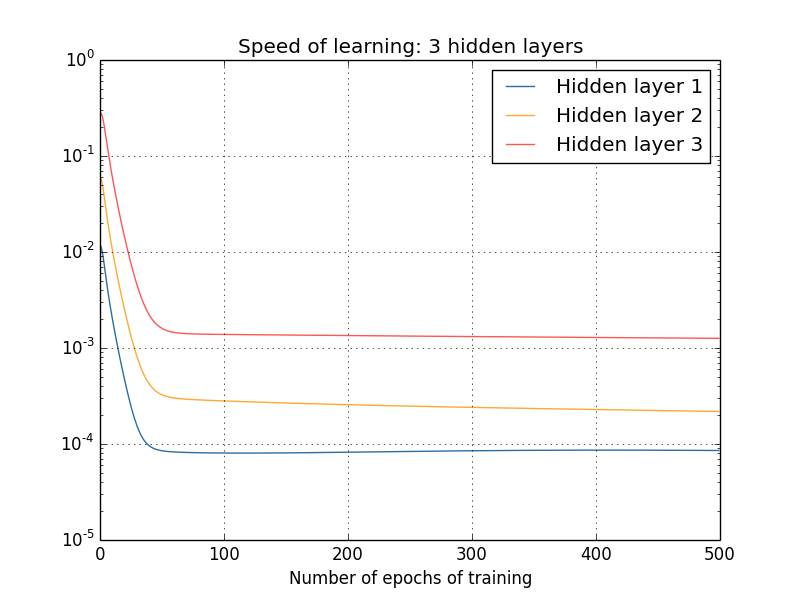
从上图可以看到,越靠近输出层的隐藏层具有越高的学习速率,这个就是我们所说的梯度消失的问题,神经网络层数越多,梯度下降越明显,神经网络层数过多可能导致开始的神经网络梯度变化很小,收敛困难,同时梯度消失的问题又导致对于激活函数响应的问题,这就是我们提到的梯度消失问题。
上面的说明都是从实验证明上体现了梯度消失的问题,下面我们对梯度消失的原因进行详细说明:
上图中我们构造了一个最简单的神经网络,每一层只有一个神经元,一般来说权重$w$都小于1,实际上对于激活函数(假设激活函数为sigmoid函数),则sigmoid函数的梯度最大值为0.25,则$|w_j \sigma’(z_j)| < 1/4$由此可得,梯度存在指树下降趋势,由此导致梯度消失。
在了解了梯度消失后我们就可以介绍一下各种激活函数了实际上主要介绍三类,分别为sigmoid函数,tanh函数以及ReLU函数。对于不同的激活函数我们主要看几点:
- 1.激活函数是否对整个实数空间适用(映射整个实数空间);
- 2.激活函数的导数情况;
其中第一点是对激活函数的要求,第二点是判断激活函数好坏的特征,这三类激活函数的函数特征在网上很多资料上都有,我们就这几种函数来说明他们之间的优劣和各自的特点。首先是sigmoid函数,sigmoid函数在深度学习早期是使用很广泛的函数,在我们刚刚学习深度学习的时候一般是以此函数作为模板的,这个函数满足我们第一点的情况,对于$[-\infty,+\infty]$区间都能够映射到$[-1,1]$之间,且求导简单。但是如我们以上分析的sigmoid函数存在几个问题,第一个:梯度消失的问题,在值极小的情况下sigmoid函数梯度趋近于0,由此导致在多层神经网络中收敛缓慢。特别是在深度神经网络中,梯度消失现象更加明显。第二:sigmoid输出的数学期望不为0,由此导致每一层神经元在传递过程中得到上一层的非0均值的信号叠加的输入。针对第二个问题,有学者引入了tanh函数,tanh函数与sigmoid函数十分相似,只是均值为0。针对第一个问题,有学者引入了ReLU函数,ReLU函数简单,计算极快,但是ReLU的问题在于非0均值以及对于小于0的输入,梯度都为0,神经元不激活。针对ReLU的问题,有很多学者对ReLU函数进行了改进,得到了一系列ReLU函数的变体,在这篇文章中就不进行详细的讨论,在后续文章中会陆续更新关于tensorflow2.0以及一些其他典型网络的相关实现。