Kafka原理与应用
条评论Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。提高Kafka我们首先从消息队列入手,然后再看看Kafka的架构设计存在的特点以及其应用。
消息队列
什么是消息队列,简单的来说消息队列(Message Queue)是一种进程间通信或同一进程的不同线程间的通信方式。消息队列可以理解为前后端的一个中间件,对于一般应用来说,由前端直接访问后端或者后端向前端推送消息,这样的模式存在着几个问题:1.前后端应用耦合性的问题;2.程序异步执行问题;3.流量控制问题;而消息队列的出现就是针对以上几个问题的一个解决方案。
以一个简单的例子来说明消息队列的应用场景,比如秒杀系统,在短时间内会存在大量的用户请求,这些请求如果全部都由后台来进行处理,则会导致后台压力大大提高,甚至会出现无法响应的问题,而前端用户需要等待的时间也大大延长,为了能够处理以上问题,我们通过一个消息队列快速存储所有用户消息,由于队列是一个先进先出的存储模式,因此通过消息队列的形式保证用户请求都能够请求到,然后后台逐步进行响应,从前端用户来说降低了请求无法响应的概率,同时后台也能够大大减轻服务压力。但是这样做也会出现一个问题,就是我们将用户请求发给消息队列后,用户接收到处理完成信息,但是这并不代表消息已经被处理了,因此需要重新在后台处理完消息队列后的消息后再提供反馈确认消息处理完成,当然采用消息队列虽然能够解决一些问题,但是滥用消息队列也会造成一些问题,主要包括:
- 系统可用性降低: 系统可用性在某种程度上降低,为什么这样说呢?在加入MQ之前,你不用考虑消息丢失或者说MQ挂掉等等的情况,但是,引入MQ之后你就需要去考虑了!
- 系统复杂性提高: 加入MQ之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!
- 一致性问题: 我上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了!
提出以上问题只是为了说明消息队列能够对系统负载有极大的提高,但是我们也不能忽略其带来的副作用,什么时候使用消息队列,以及如何使用需要我们仔细思考。
Kafka原理说明
其实kafka也就是是一种消息队列,只是其在简单的消息队列的基础上进行了更加完整的架构,我们下面仔细说明一下kafka的架构信息。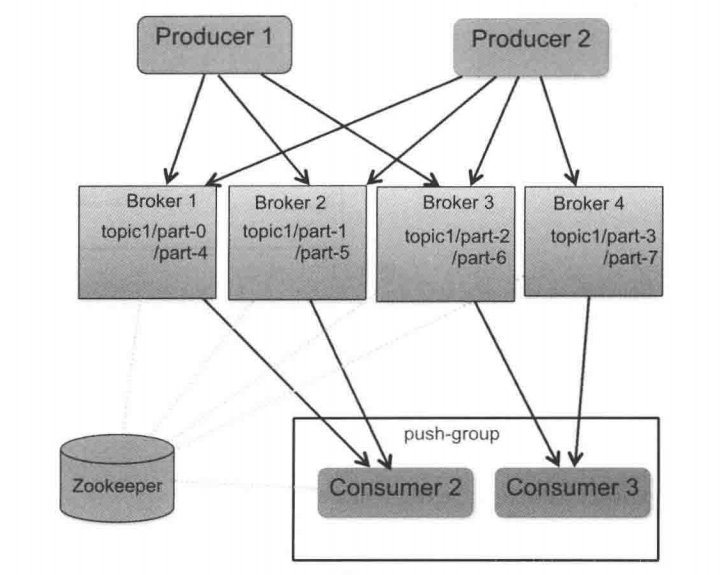
从上面的架构图中可以看到,kafka的几个特点以及几个名词,主要包括:
- 生产者(Producer):消息和数据生产者
- 代理(Broker):缓存代理,Kafka的核心功能
- 消费者(Consumer):消息和数据消费者
实际上kafka的过程就是从生产者生产了数据放在Broker中,Broker承担一个中间缓存和分发的作用,负责分发注册到系统中的Consumer,实际上Consumer通过主动取数据的方式能够取到kafka中的消息,这一个整体的流程就是kafka作为一个消息队列的整个过程。在这里Broker可以看做一个服务器集群,他们通过zookeeper进行负载均衡。此外还有一些术语,包括topic,partition,以及message,kafka将消息组合为一个或多个topic进行存储,实际上topic就是某一类消息的汇总,我们可以将其理解为一个文件名,或者是一个文件描述,在topic之下有partition,partition为消息存储的实际结构,一个topic的消息可以保存到多个partition中供消费者读取,每个消息都被标识了一个递增序列号代表其进来的先后顺序,并按顺序存储在partition中。这个标识在kafka中称为id,实际上消费者能够通过id以及其偏移量进行随机的读取消息,实现了消息的灵活读取。
作为一个消息队列,kafka提供了消息持久化的功能,即消息能够保存到文件中进行持久化,同时kafka也支持备份机制,对于kafka来说,所有Node都提供一份完整备份,也就是说当有N个副本时,N个副本都在ISR中,N-1个副本都出现异常时,系统依然能提供服务。具体的kafka的消息持久化和备份机制可以参看kafka官网介绍。
Kafka应用实践
kafka做为一个消息队列,其设计是十分精巧的,但是他的使用和部署方法却是十分方便,在windows下也能够方便的进行部署和使用,正常情况下按照参考资料都能够部署成功,但是有几个问题是需要确认的,第一个问题在于kafka的版本,在我尝试过程中3.5以上的版本在部署的过程中可能出现问题,因此建议采用3.4.X的版本部署。