tensorflow-二十七弹
条评论tensorflow的学习进行到这个阶段,实际上已经处于一个入门阶段了,在前面的学习过程中我们着重介绍了CNN的构造以及实现过程,另外也提及了一些关于爬虫的知识以及一些关于机器学习的数学基础,现在感觉整个CNN的过程已经掌握得差不多了,剩下就是各种CNN网络得实现了,这个实际上就跟拼接积木差不多了,是一些调参得过程,其中如果进行深入的数学分析就太复杂了,所以在这里先放一放,先接触一下其他的类型的深度网络,然后再回来研究网络的构造问题,下面主要进行RNN的学习:
RNN:循环神经网络,Recurrent Neural Network。神经网络是一种节点定向连接成环的人工神经网络。这种网络的内部状态可以展示动态时序行为。不同于前馈神经网络的是,RNN可以利用它内部的记忆来处理任意时序的输入序列,这让它可以更容易处理如不分段的手写识别、语音识别等。——百度百科
实际上RNN更重要的作用应该是对于语义的识别,百度百科的定义我们看看就行了。本次学习以及代码参考一下文章以及博客(如有侵权,联系删除):
使用TensorFlow实现RNN模型入门篇1
RNN入门详解及TensorFlow源码实现–深度学习笔记
Recurrent Neural Networks Tutorial, Part 1 – Introduction to RNNs
Recurrent Neural Networks in Tensorflow I
Recurrent Neural Networks Tutorial, Part 2 – Implementing a RNN with Python, Numpy and Theano
什么是RNN
既然要学习RNN,那么我们就得先了解一下到底什么是RNN,实际上RNN被创造得目的在于充分利用序列数据的前后文信息。在传统的神经网络中假设没一次的输入和输入(每一次训练)是独立的,但是实际上在生活中我们面对很多问题的时候都会有一个上下文的关系,比如写文章之类的。我们语句的不同输入顺序可能有完全不同的意思,RNN就是来处理这样的问题的。另外我们从另一个角度来思考RNN,也就是我们通常说的记忆,意思就是能够从以前所有的输入数据中提取信息。理论上来说RNN能从记忆无限长时间的信息,但是在实际应用过程中会限制回溯的步长。
这里要祭出那张经典的图了: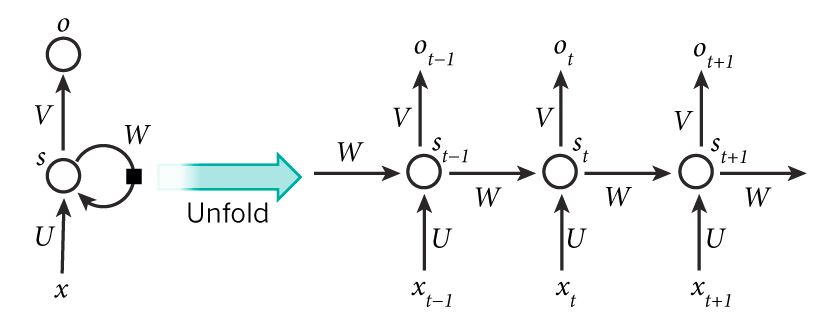
这张被引用过无数次的图很形象的说明了RNN的过程,实际上左边是RNN的过程,右边是RNN展开的过程,如果我们关心五个单词的句子,整个网络就可以展开成一个五层的神经网络,每个单词就是一层,整个结构为:
- $x_t$ is the input at time step $t$. For example, $x_1$ could be a one-hot vector corresponding to the second word of a sentence.
- $s_t$ is the hidden state at time step t. It’s the “memory” of the network. s_t is calculated based on the previous hidden state and the input at the current step: $s_t=f(Ux_t + Ws_{t-1})$. The function f usually is a nonlinearity such as tanh or ReLU. $s_{-1}$, which is required to calculate the first hidden state, is typically initialized to all zeroes.
- $o_t$ is the output at step t. For example, if we wanted to predict the next word in a sentence it would be a vector of probabilities across our vocabulary. $o_t = \mathrm{softmax}(Vs_t)$.
上面就是几个参数的说明,实际上比较简单也就没有必要再翻译了,看看就好了,下面就上面这个过程做一个简单的说明:
- 实际上可以认为$s_t$是一个记忆网络,能够记录以前所有的信息,而输出层$o_t$的计算仅依赖于时刻$t$的记忆,但是实际情况会复杂一些,因为$s_t$并不能记忆住前面太多步的信息(实际上也没有必要记住前所有步的信息)
- RNN实际上展开后每一层都是共享的同一参数,所不同的仅仅是输入值,通过此种方式极大的减小了参数的数目(序列输入,输入网络层数可能极大)
- 实际上对于部分应用来说不是所有的中间输出步骤都是有效的,我们仅仅关心最后的输出,同样对于输入我们也不需要关心每次的输入,RNN的主要特征是它的隐藏状态,这些隐藏状态可以获取序列数据的信息。
RNN的应用
这里就随便谈谈了,实际上RNN做的最多的还是语义理解以及机器翻译工作,最常用的RNN模型问LSTM。具体的介绍参看Recurrent Neural Networks Tutorial, Part 1 – Introduction to RNNs
语言模型
假设有一个m个字母的句子,我们建立如下一个语言模型去预测一个句子出现的可能性:
$$\begin{aligned} P(w_1,…,w_m) = \prod_{i=1}^{m} P(w_i \mid w_1,…, w_{i-1}) \end{aligned}$$
通俗的来说,一个句子出现的可能性就是每个单词在它之前单词出现后可能性的后验概率的乘积。语言模型的重要之处在于可以通过语言模型形成一个打分机制,在机器翻译等工作中可以被用来选择最佳的翻译方式。语言模型的另外一个作用在于句式生成,如果我们有了足够丰富的句子,则我们可以通过构建好的语言模型生成句式。从上面的模型可以看出每一个单词生成的可能性都取决于其之前的所有单词,实际上很多模型都并不需要或者说从内存和计算时间的角度来说都无法关注到这么长远的记忆,因此我们会限制记忆的长度,并且对不同时长的记忆给不同大小的权重进行约束。
RNN实现
好了以上就是RNN的一些介绍,以及其的应用,为了更加快速的入门RNN,我们通过tensorflow构建一个简单的网络对我们生成的简单数据进行训练。
训练数据集的说明
输入序列数据X:在第$t$步,$X_t$有百分之五十的可能性为1,另外百分之五十可能性为0,则$X$可能为$[1,0,0,1,1,1…]$
输出序列数据Y:对于任意第$t$步,$Y_t$有百分之五十的可能性为1,如果$X_{t-3}$步为1,则$Y_t$为1的可能性增加百分之50,如果$X_{t-8}$步为1,则$Y_t$为1的可能性下降百分之25%,通过这样的模式就确定了输出数据不仅和当前的输入有关,还与前几次的输入情况有关系;这样的一个网络实际上算是比较简单的网络结构了,我们根据以上生成的数据进行模型的构建。
模型构建
对于上面描述的这个简单问题,模型构建就很简单了,实际上对于一个模型来说我们首先要考虑的就是他的输入和输出问题,对于RNN模型我们输入是一个0或1的数据$X_t$以及上一个状态矢量$S_{t-1}$,输出$S_t$为可能性分布矢量,$P_t$是输出结果的预测,则有如下公式:
$$
\begin{aligned}
&S_t=tanh(W(X_t\cdot S_{t-1})+b_s)\
&P_t=softmax(US_t,+b_p)
\end{aligned}
$$
@表示向量的组合,$X_t$是一个二进制编码向量,$W$,$b_s$,$U$分别为状态矩阵,严格的来说应该证明为什么迭代就能够收敛到正确解,实际上对预测结果求导,然后导数为0分析其收敛特征,但是一般来说神经网络对于我们来说是一个黑盒过程,所以我们不太关心其背后的数学原理,假设能够收敛,则整个模型为:
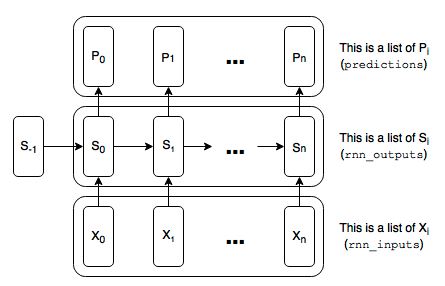
上图应该是比较好理解的图,$S_{-1}$为初始状态,可以都为0,然后进行循环计算,实际上训练过程有一个回溯的过程,我们在RNN的数学基础中再去讨论RNN的反向传播过程以及设置记忆长度为多少才合适的问题,现在我们只讲RNN的构造,RNN的构造主要是构造一个RNN_Cell然后复用就好了,主要代码为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46x = tf.placeholder(tf.int32, [batch_size, num_steps], name='input_placeholder')
y = tf.placeholder(tf.int32, [batch_size, num_steps], name='labels_placeholder')
#RNN的初始化状态,全设为零。注意state是与input保持一致,接下来会有concat操作,所以这里要有batch的维度。即每个样本都要有隐层状态
init_state = tf.zeros([batch_size, state_size])
#将输入转化为one-hot编码,两个类别。[batch_size, num_steps, num_classes]
x_one_hot = tf.one_hot(x, num_classes)
#将输入unstack,即在num_steps上解绑,方便给每个循环单元输入。这里可以看出RNN每个cell都处理一个batch的输入(即batch个二进制样本输入)
rnn_inputs = tf.unstack(x_one_hot, axis=1)
#定义rnn_cell的权重参数,
with tf.variable_scope('rnn_cell'):
W = tf.get_variable('W', [num_classes + state_size, state_size])
b = tf.get_variable('b', [state_size], initializer=tf.constant_initializer(0.0))
#使之定义为reuse模式,循环使用,保持参数相同
def rnn_cell(rnn_input, state):
with tf.variable_scope('rnn_cell', reuse=True):
W = tf.get_variable('W', [num_classes + state_size, state_size])
b = tf.get_variable('b', [state_size], initializer=tf.constant_initializer(0.0))
#定义rnn_cell具体的操作,这里使用的是最简单的rnn,不是LSTM
return tf.tanh(tf.matmul(tf.concat([rnn_input, state], 1), W) + b)
state = init_state
rnn_outputs = []
#循环num_steps次,即将一个序列输入RNN模型
for rnn_input in rnn_inputs:
state = rnn_cell(rnn_input, state)
rnn_outputs.append(state)
final_state = rnn_outputs[-1]
#定义softmax层
with tf.variable_scope('softmax'):
W = tf.get_variable('W', [state_size, num_classes])
b = tf.get_variable('b', [num_classes], initializer=tf.constant_initializer(0.0))
#注意,这里要将num_steps个输出全部分别进行计算其输出,然后使用softmax预测
logits = [tf.matmul(rnn_output, W) + b for rnn_output in rnn_outputs]
predictions = [tf.nn.softmax(logit) for logit in logits]
# Turn our y placeholder into a list of labels
y_as_list = tf.unstack(y, num=num_steps, axis=1)
#losses and train_step
losses = [tf.nn.sparse_softmax_cross_entropy_with_logits(labels=label, logits=logit) for \
logit, label in zip(logits, y_as_list)]
total_loss = tf.reduce_mean(losses)
train_step = tf.train.AdagradOptimizer(learning_rate).minimize(total_loss)
从以上代码可以看出,输入有$n$个单元,其中$n$为我们记忆回溯的步长,state_size为隐藏层的状态向量,长度根据需求和输入确定,我们直接看核心部分rnn_cell函数,这个函数定义了RNN的核心运算,首先是W和b的定义,然后是定义运算,整个运算过程为:tf.tanh(tf.matmul(tf.concat([rnn_input, state], 1), W) + b),实际上就是公式中所提到的,这里有一个concat运算,这个运算时将两个矩阵进行连接,由于最开始的时候已经将编码方式转换为了one-hot编码,one-hot编码实际上意思就是采用你一个0-1的向量来对参数进行编码,组成一个参数矩阵,具体的解释可以参考OneHot编码知识点,通过这样的编码方式编码成可理解的向量,然后通过unstack解绑,得到每一个batch每一个step的输入,最后通过循环填充数据,然后定义输出层与中间层的W与b,进行误差的估计并采用AdagradOptimizer(随机梯度下降)的方法进行迭代。好了,整个过程就介绍到这里,下面一节就准备对RNN的数学基础进行学习。