concul服务注册与发现
条评论关于服务注册于发现Consul
微服务
对于微服务的应用来说由于客户端以及服务端应用接口特别多而且复杂,对于各个客户端之间的通信是一件很复杂得事情,通常情况下一个客户端出现了问题而停止或者更换了端口或者部署机器的地址都会导致其他与之相关联的服务都需要切换端口和IP,这会带来特别大的影响,为了降低服务部署和修改带来的影响于是产生了服务注册于发现的机制。不管什么架构设计,脱离了需求来谈架构就是空谈,但是对于一个公司有着许多不同的业务板块,每个板块之间基本独立但是又有区分,因此使用微服务的架构就是很有必要的了(避免单个服务做得过大导致一旦出现问题整个系统崩溃),提到服务注册和服务发现就不得不提一下微服务的构架,如果采用单体服务的模式,整个系统前后端统一,单体化部署使用服务注册于服务发现的框架反而增加了程序负担这样就得不偿失了:
微服务这个概念实际上相对来说比较新,从2012年提出到现在也才经过6年的时间,实际上从微服务被普遍认可和接收也就从2015年开始,我前几天读完了一本关于微服务架构的书也对微服务有了些了解,实际上整个微服务就是我们程序设计中的高内聚低耦合的集中体现。谈到微服务就不能不提SOA,这两种架构之间有着千丝万缕的联系,我实际上也没有真正执行过SOA架构或者微服务架构的应用(以后会执行的~)我只能谈谈我的理解了,对于一个应用来说,采用SOA架构主要过程是首先对业务整体情况进行了解,然后将整体业务拆分为独立的业务逻辑,然后对每一块业务逻辑流程进行分别开发,最后进行集成;而采用微服务的架构可能拆分得更加细粒度,举一个例子如图:

图片来自CSDN博客侵删联系(wuwei_cug@163.com)上面一张图很清晰的说明了SOA与微服务之间的差别,SOA以业务逻辑为粒度构建应用,而微服务架构构建更加细的粒度的独立应用,然后将应用组合起来形成业务逻辑。简单的来说就是对于服务的理解有差异,当然实际上SOA还有EBS企业总线,数据总线等概念,在这里就不详细的描述了。
Consul原理
从上图中可以看到对于一件简单的应用微服务会将其拆分为很多服务然后提供接口,那么实际上这么多服务的管理自然而然就成为了一个需要考虑的问题,实际上对于这个问题SOA也出现过,而SOA采用一个很复杂的逻辑EBS总线去管理所有服务间的通信与调度以及服务的健康检查,实际上微服务并不需要这么一个复杂得逻辑,因为微服务本身的接口很清晰应用服务之间逻辑界限很明确,因此不需要一个过于复杂得调度总线,但是也需要一个服务注册于服务发现的管理,这个就是我们要着重介绍的Consul,在这里我只介绍Consul的使用以及服务的注册,更多的内容还在摸索当中:
Consul的架构如图:
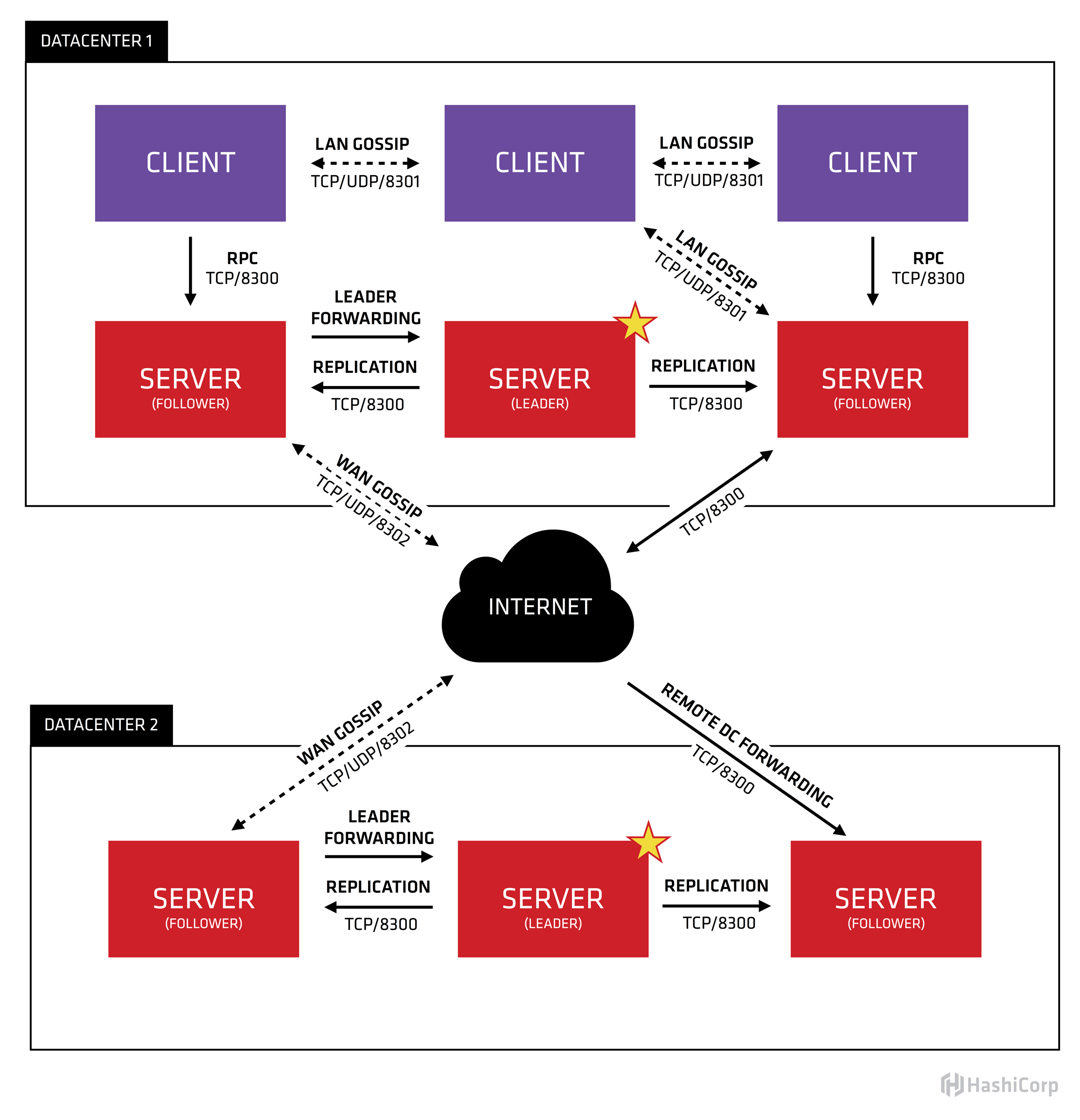
上面这张图示从官网下载下来的图,随之还有官网的描述,英文好的同学可以直接看原文,我会在每一个描述上添加上自己的理解。
Let’s break down this image and describe each piece. First of all, we can see that there are two datacenters, labeled “one” and “two”. Consul has first class support for multiple datacenters and expects this to be the common case.
这里提到了一个特性,多数据中心支持,数据中心实际上只是一个局域网络比如我们的内网,私有云等,一般数据中心之间的数据是不进行交互的实际上不太能明白多数据中心支持的意义在哪里,是不是为了内外网部署应用的时候能够有一个统一的管理?Within each datacenter, we have a mixture of clients and servers. It is expected that there be between three to five servers. This strikes a balance between availability in the case of failure and performance, as consensus gets progressively slower as more machines are added. However, there is no limit to the number of clients, and they can easily scale into the thousands or tens of thousands.
上面谈到了关于数据中心,我们暂时不去管数据中心,我们看每一个数据中心中的部署,对于每一个数据中心其构成为分部式部署架构,主要分为client模式和server模式上面这段说明了server模式和client模式的数量,对于这两种模式其实官网也有一个解释:
Client - A client is an agent that forwards all RPCs to a server. The client is relatively stateless. The only background activity a client performs is taking part in the LAN gossip pool. This has a minimal resource overhead and consumes only a small amount of network bandwidth.
Server - A server is an agent with an expanded set of responsibilities including participating in the Raft quorum, maintaining cluster state, responding to RPC queries, exchanging WAN gossip with other datacenters, and forwarding queries to leaders or remote datacenters
官网的解释很抽象,我不太想去翻译,翻译出来没有太大的意义,我在这里谈谈我自己的理解,实际上整个服务注册说明所有注册的服务都有一个统一的维护那就是所说的LAN gossip pool,在这个数据池中存储了所有的注册服务,而客户端的作用就是有一个服务注册进来了,那么就将这个服务添加到LAN gossip pool中,另外客户端的作用就是转发查询请求给服务端。客户端的功能比较简单,相对复杂的是服务端,服务端包含客户端的功能此外还需要进行健康检查和响应查询,服务端包含leader和follower,理论上每个服务端都对注册的服务进行健康检查,然后发送给leader,通过投票机制来确定注册的服务的健康状况,因此官方推荐的服务端为3个或5个,必须为奇数个,且不宜太多增加check的花销。
All the nodes that are in a datacenter participate in a gossip protocol. This means there is a gossip pool that contains all the nodes for a given datacenter. This serves a few purposes: first, there is no need to configure clients with the addresses of servers; discovery is done automatically. Second, the work of detecting node failures is not placed on the servers but is distributed. This makes failure detection much more scalable than naive heartbeating schemes. Thirdly, it is used as a messaging layer to notify when important events such as leader election take place.
上面这一段话中唯一要注意的就是那个thrid,其他亮点在上一个客户端和服务端的解析中已经说明了,因此着重讲讲我对第三点的理解,实际上选举出leader是一个很重要的部分,consul是通过Raft协议选举出leader,具体的方法我查找了很多地方在stackoverflow上略有提及,是通过一个叫randomized timers的方法选取的,具体的方法需要参看论文如果我有时间看论文的话在具体说说这个方法吧。现在没有时间看所以暂且放一放The servers in each datacenter are all part of a single Raft peer set. This means that they work together to elect a single leader, a selected server which has extra duties. The leader is responsible for processing all queries and transactions. Transactions must also be replicated to all peers as part of the consensus protocol. Because of this requirement, when a non-leader server receives an RPC request, it forwards it to the cluster leader.
这里承接上面一段说了一些关于服务节点同步以及leader事务同步的问题,这个深入讨论就涉及代码层了,等我有时间阅读代码之后再讨论。
- The server nodes also operate as part of a WAN gossip pool. This pool is different from the LAN pool as it is optimized for the higher latency of the internet and is expected to contain only other Consul server nodes. The purpose of this pool is to allow datacenters to discover each other in a low-touch manner. Bringing a new datacenter online is as easy as joining the existing WAN gossip pool. Because the servers are all operating in this pool, it also enables cross-datacenter requests. When a server receives a request for a different datacenter, it forwards it to a random server in the correct datacenter. That server may then forward to the local leader.
- This results in a very low coupling between datacenters, but because of failure detection, connection caching and multiplexing, cross-datacenter requests are relatively fast and reliable.
In general, data is not replicated between different Consul datacenters. When a request is made for a resource in another datacenter, the local Consul servers forward an RPC request to the remote Consul servers for that resource and return the results. If the remote datacenter is not available, then those resources will also not be available, but that won’t otherwise affect the local datacenter. There are some special situations where a limited subset of data can be replicated, such as with Consul’s built-in ACL replication capability, or external tools like consul-replicate.
上面提到的关于多数据中心的作用以及使用的集中体现,实际上我认为没有太大的必要做多中心,本省数据中心之间也不会互相访问,不知道多数据中心的管理意义在哪里,想来不过也就是增加了数据中心的扩展性,但是实际应用中不会多中心部署吧,与其这样还不如每个私有云部署一个来的方便,不过如果多中心之间有通信的话可能还是有些作用的,这个可能需要应用场景的支撑了,现在我还想不出有什么意义。In some places, client agents may cache data from the servers to make it available locally for performance and reliability. Examples include Connect certificates and intentions which allow the client agent to make local decisions about inbound connection requests without a round trip to the servers. Some API endpoints also support optional result caching. This helps reliability because the local agent can continue to respond to some queries like service-discovery or Connect authorization from cache even if the connection to the servers is disrupted or the servers are temporarily unavailable.
上面这段提到了一种客户端缓存数据的特殊情况,主要是为了提高可靠性,通过客户端缓存某些数据以免在客户端与服务端通信不畅或服务端暂时挂起的状态下还能够保持响应的可用性。
上面讲了一大段对于架构的介绍以及高可用性的部署,客户端服务端的分工以及各种协议的通信实际上就是为了解决服务注册和发现的问题,看似一个很小的问题却考虑了一个这么庞大的架构来处理就存在一个有没有必要的问题,对于少量服务的应用需求实际上光是理解这个consul就是一个很高的成本,采用服务注册于发现的机制完全是没有必要的,但是对于企业级的应用来说却是很有必要的,其必要性主要体现在:1.服务运维,从运维的角度来说服务的动态变化实际上极大的增加的运维测试的负担,必须要对服务有一个集中管理的过程;2.从可扩展性的角度来说,通过此种方式在分布式架构下大大提高了服务的可扩展性,甚至可以说是随意扩展;3.从开发的角度来说通过服务发现统一了接口,避免由于部署的差异导致接口的变化,当然这个实际上也可以理解为运维测试的好处。
consul使用
提了一大堆的介绍,从开发的角度说一下Consul的使用,因为死单机所以我采用的是单机Docker部署的方式,安装环境为Windows10 开发语言为python3.6.x。首先运行consul:参考网上教程运行了一个单节点的consul,这个是最简单的运行,多节点就是添加节点,这个以后再说。运行完成之后在浏览器可以看到如下页面:
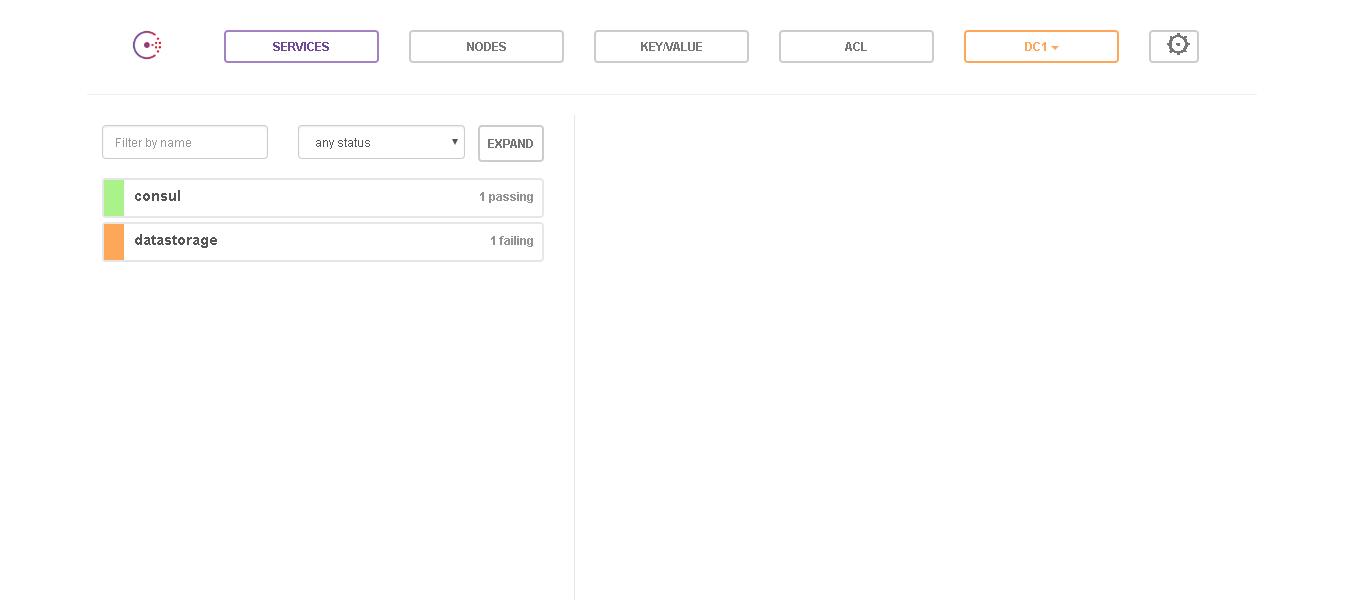
从上面的界面上可以看到服务运行的状态信息,有一个consul 的节点,另外运行了一个datastorage的服务,不过这个服务failling,是一个失败的服务,因为我停掉了服务器。我们可以根据上面的参考教材通过命令去注册服务,当然我这里使用python-consul直接在服务启动的时候进行注册,具体的代码为:
1 | import sys |
以上的项目具体代码参看我的Github实际上就是给出注册的服务的id,服务名,然后给一个check的地址,然后consul的server会查询这个check的地址确认服务是否可用,在上面我用的是IP地址,因为服务搭建在docker中,如果用localhost是无法访问到的因此注册的时候要用绝对地址。
以上代码简单的介绍了一下服务注册,由于这个代码只是提供接口,并不需要接额外的服务,因此并不需要使用服务发现模块,具体使用服务发现模块也很简单就是通过服务名或服务id查询可用的host以及port然后请求就好了,如果查询不到则说明服务不可用。