kd树的构建
条评论 在这个普天同庆的光棍节的大日子默默的睡了个天昏地暗,然后爬起来写了个专利。实际上写专利的时候又突然搞懂了KD树的构建算法,果然工作使我快乐,以前的时候一直在用KD树,不过都是用的开源的库,所谓的混合索引方式也只是在开源库的基础上进行代码的改造,对于原理的理解还是不够深入,今天在写专利的时候重新梳理了一次觉得终于弄得有点明白了。
下面上一张图来说明一下这个过程: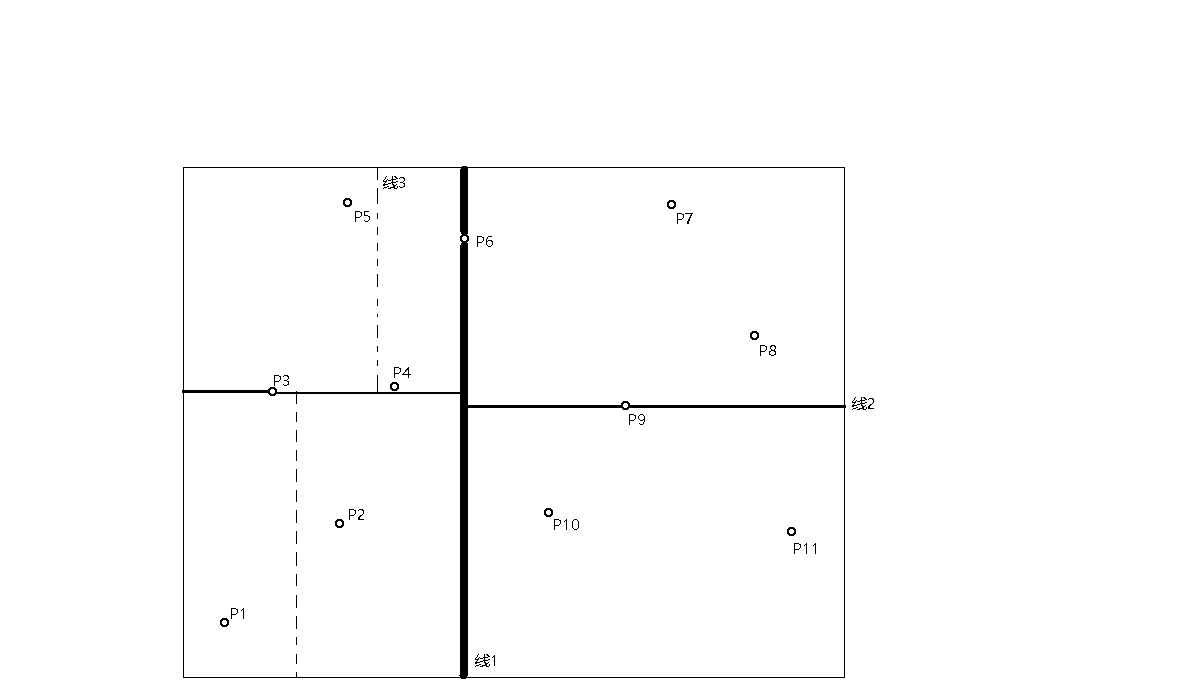
上图是二维空间KD树的划分过程,首先确定划分是从哪一个维度进行,是从x维还是从y维,一般确定维度的过程是计算数据集在各个维度的方差或标准差,从方差或标准差大的维度开始计算进行划分。确定维度后按照该维度进行排序取中位数将点集划分为两个部分,如线1所示,进行第一次划分之后对左右两个点集进行第二次划分如线2所示,然后依次进行划分直到所有点都只属于某一个划分。上图是对于二维点的一个划分,实际上对于高维的点也差不多,由于高维画起来比较麻烦就懒得画了。在解决划分和构造的问题的基础上我们就需要问,如果构造好了一棵树,怎么进行最近邻查询,这个就是我们下面需要讨论的问题。
我们用一幅图来展示整个搜索过程:
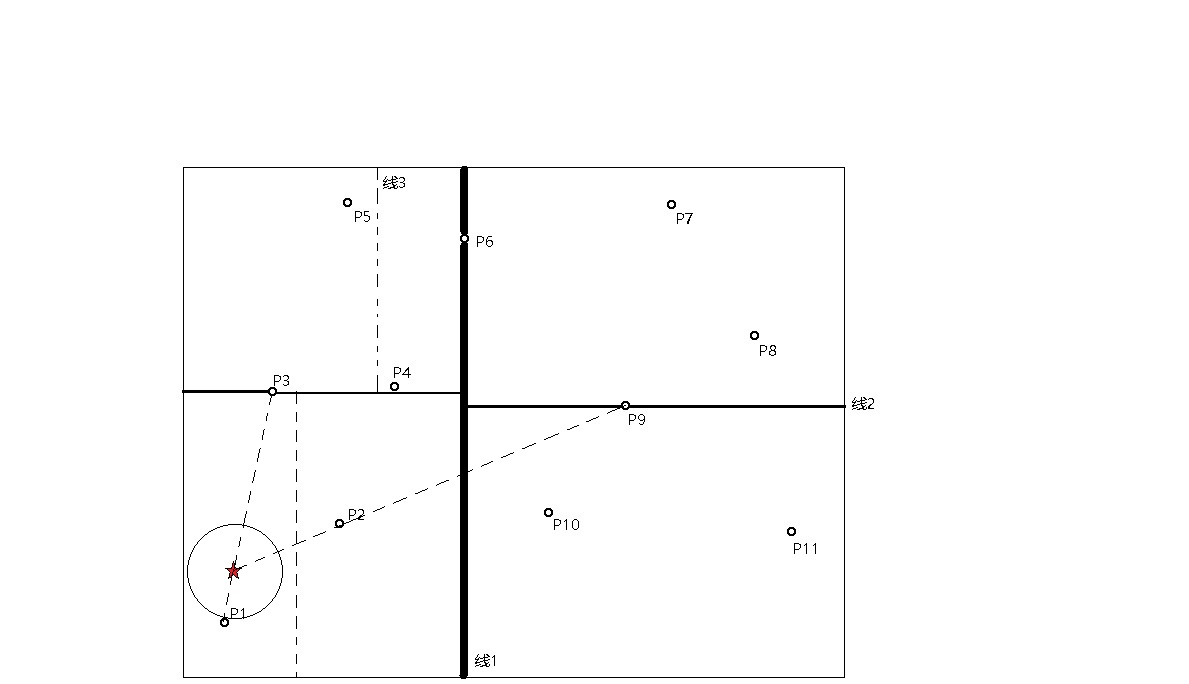
以上就是我们的最近邻的搜索过程,红色的五角星为目标点,首先计算目标点到根节点的距离,构成一个超球,判断各个区域是否与超球有相交,通过判断可知P8与P11所在空间与超球没有交集因此忽略这两个部分,然后计算与P3和P9的距离,与根节点的距离比较,如果小于根节点的距离则缩小这个超球,为点到P3的距离,据此可以忽略整个P6右侧所有节点,以及P4节点所在空间;然后遍历剩下的节点,找到最近的节点P1。
参考资料:
https://leileiluoluo.com/posts/kdtree-algorithm-and-implementation.html
https://www.cnblogs.com/earendil/p/8135074.html